
昨天到淡江大學參加大數據分析與 R 論壇,與談的過程中陳景祥老師提出了資料分析工具比較的討論議題。本來是想強調智庫驅動徵才要找怎樣的人,一不小心被引導到 R 與 Python 的比較 (後來想來,根本是陳老師在挖坑…)。網路上其實已經很多人討論過這個題目,譬如這篇《數據科學界華山論劍:R與Python巔峰對決》,整理得非常完整,根本就意圖 closed 這系列的討論。
這邊想補充一個會議上沒來得及說清楚的觀點。從資料分析的功能面上,即便 R 跟 Python 如果做一個比較表,也會發現兩邊不分上下,比不出一個所以然。筆者簡單將資料分析的方法分成四大類:Regression, Classification, Clustering and Dimensionality reduction,在下表中列出幾個代表性的演算法,接著再指出 R 與 Python 的對應資料分析套件。
看完這張表格就會理解 R 與 Python,這兩種語言在資料分析工具發展的思維上是有決定性差異的,筆者認為這個差異將決定使用者解決真實問題的方式。對於 R語言來說,各種演算法散落在各種套件當中,所以 R user 在做資料分析的時候,必須要先思考它所面對的問題需要載入怎樣的套件才能解決,如果這個套件提供的演算法仍不夠完善,R user 會先嘗試對該演算法做校正,而不是去思考要不要換其他套件庫。至於 Python user 在做資料分析時,當他載入 scikit-learn 之後,他有超級豐富的武器庫可以去嘗試,當某個演算法效果不如預期時,Python user 會傾向先換別的演算法再試一次看看。
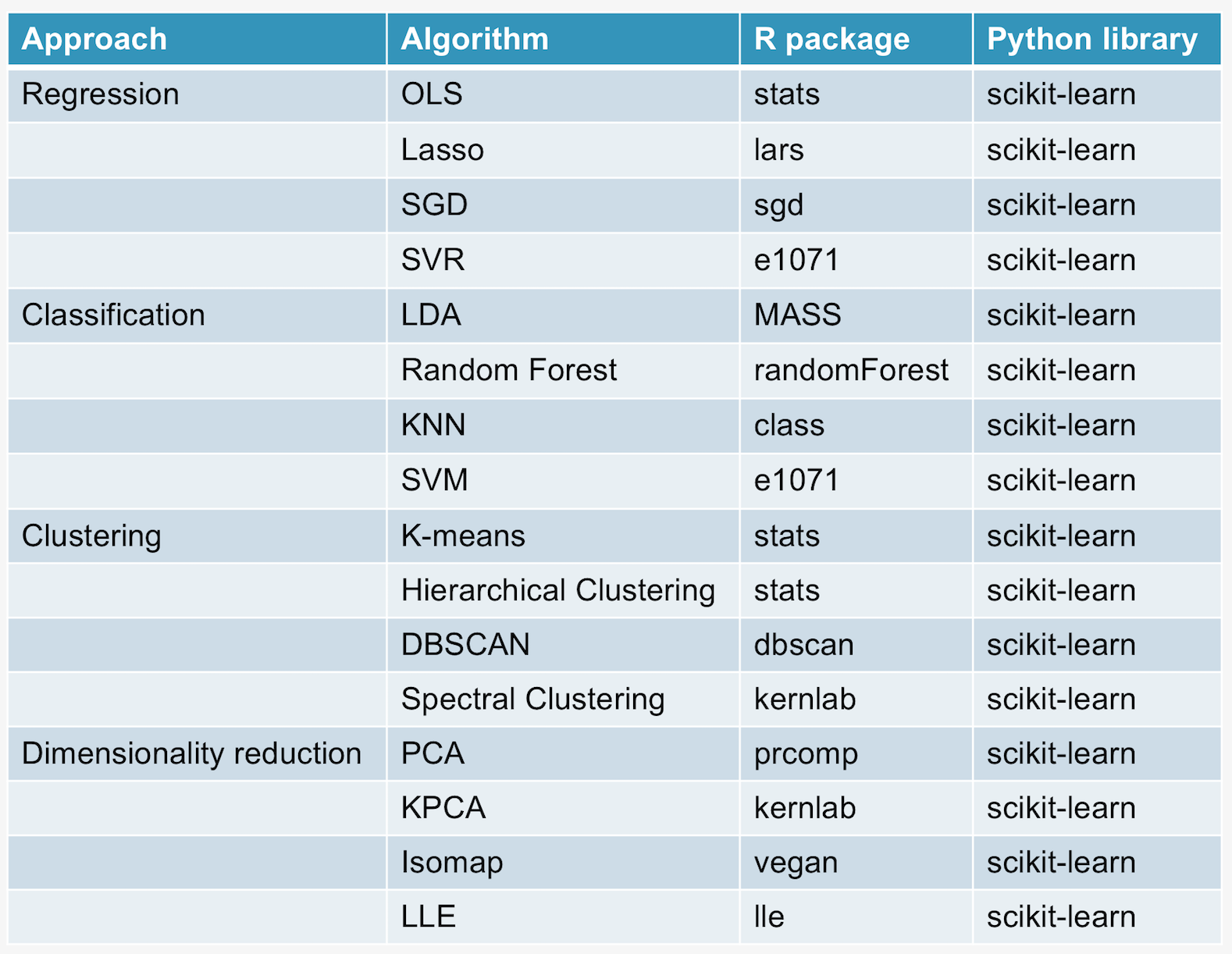
從套件功能比較 R 與 Python
再次強調,在演算法的功能面以及模型優化上 R 與 Python 其實都可以做。就筆者自身經驗 R users 在討論資料分析遇到瓶頸的時候會先討論 outlier, overfitting, regularization。而 Python users 在討論的時候會先盤點用過哪些演算法,哪些演算法可以解決某某問題。筆者認為這是這兩種工具發展目的所造成的差異, R 語言是隨著學術研究而發展、Python 則是基於優化資料分析的應用環境。
從企業招募的觀點來說,主管應該要思考的是做資料分析的目的為何,需要招募怎樣特質的資料分析師。詢問筆者該學習 R 或 Python 的學生,則建議思考一下你的個人特質適合,想要橫向或縱向的分配你的技能點。
特色圖片取自:ActiveState




近期迴響