台灣史上第一次的資料科學政府團訓班,由DSP 智庫驅動、國家發展委員會及開拓文教基金會聯合主辦,在班主任 行政院張善政副院長的帶領下,橫跨20個中央部會共36名成員體驗了一場用資料論政策的工作坊 (2015 8/6, 7, 13, 14)。欲知詳情,請參考DSP網站上的精彩回顧。
這場活化政府的資料思維活動之前,今年七月 DSP 智庫驅動與政治大學-ITSA社群運算與巨量資料跨校資源中心在政大替大專碩博生打造了一場資料科學夏令營 (2015 6/30, 7/1, 2, 3)[1, 2]。學生來自全台12所大學將近20種不同系所,包含資訊科學、統計學、商學、傳播學、社會學及其他領域,是一場貨真價實的跨領域工作坊。

《公共政策與治理 – 資料思考工作坊》專案實作一隅
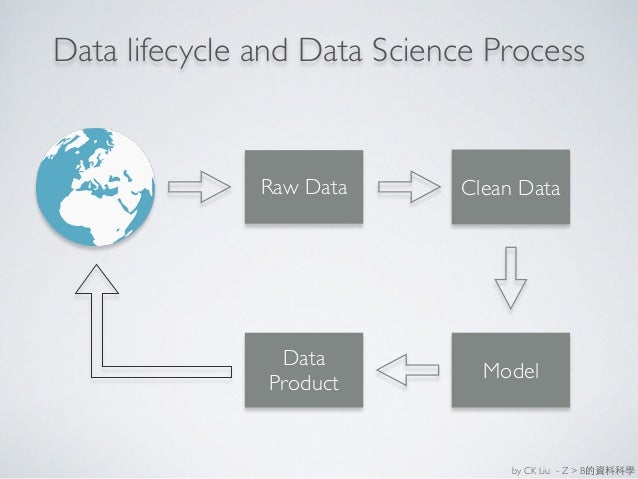
身為工作坊規劃者之一,分享一點活動設計的理念,供有意從事資料科學推廣教育的朋友做參考。以學生為主的夏令營,設計主軸環繞在完整的資料科學流程 (Data Science Process),從資料思考 (Data thinking) 開始,藉由資料盤點、資料剖析 (Data understanding) 來提出問題,進而規劃出具有數據論證基礎的資料科學應用 (Data product)。對於欲將資料科學血液注入政府架構的各部會菁英們,更加強資料科學導入的策略指導 (Data strategy) 以及政府資料、開放資料 (Open data) 的真實應用案例分享。
由於資料分析是一系列的串聯流程,需要不同領域的專家通力合作。我們設計了小組專案活動,將學員依跨部會、跨科系、跨領域、跨專業的方式進行分組,協同合作完成一場微型資料科學專案。安排的講者除了分享資料科學相關知識以及真實案例之外,還得身兼小組專案指導員,提供建議與技術的協助。
魔鬼總是藏在細節裡,真的走過幾遭才能體會當中的艱辛。近來資料科學的教育訓練嚴然是政府、企業、NGO、NPO 欲導入以數據輔佐決策的重要模式。今年9/2 (三) 由國立政治大學、淡江大學與DSP 智庫驅動聯合主辦了一場《資料科學教學經驗分享會》,這場活動邀請各方從事資料科學教育的老師一同分享課程設計、教學方法、補助工具等等的經驗談,也邀請到實際參與課程的學生分享他們的學習歷程,歡迎有意從事相關領域教學或研究的大專教師以及同好共襄盛舉。

{kind=link}
近期迴響