大數據帶來「偽相關」
第二屆資料科學愛好者年會,1300人參與的大拜拜圓滿結束,九月初參加了年會系列活動 資料科學團隊培訓及導入經驗分享會 (我跟Wush有很認真做筆記喔),對於一張關聯圖印象深刻,上吊自殺 vs. 科研經費的相關係數竟高達0.9979 (台大心理的黃從仁老師也有在年會演講中秀出這張圖!),這種八竿子打不著的關聯性,其實不是巧合,而是 Big Data 時代下必然的產物。
現今的大數據世代有個明顯特徵,就是資料氾濫,我們可以很容易地收集到許多不同來源的資料。這張圖就是透過美國數十萬筆開放資料進行一一比對所找出來的特例 (可以到 trievigen.com 找到更多例子)。要說的是,僅僅利用 Data mining 辦法找出資料欄位間的相關性,來作為組織的決策是很危險的。
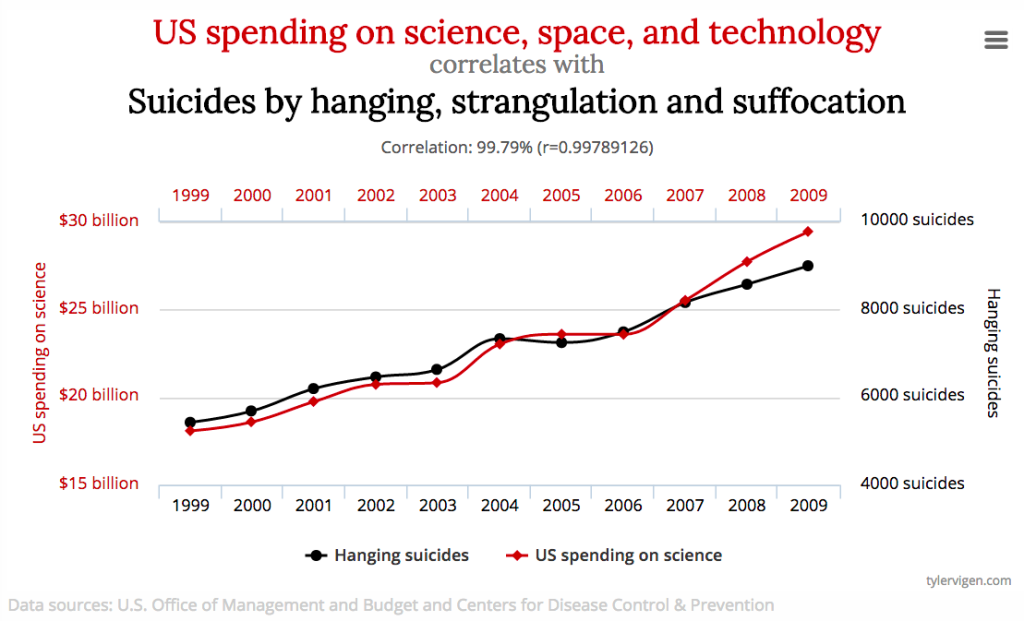
「上吊自殺 vs. 科研經費」 (相關係數 = 0.9979)
資料科學的 danger zone
Drew Conway 所提出來的 Data Science Venn Diagram 應該是目前在介紹資料科學時,最多人引用的一張圖 (可以數數看這張圖在2014資料科學愛好者年會的演講中出現幾次),其中值得注意的是Hacking Skills 與 Substantive Expertise 的交集為 Danger Zone。白話的說法是「會跑 Data Mining,不表示能下正確決策」。
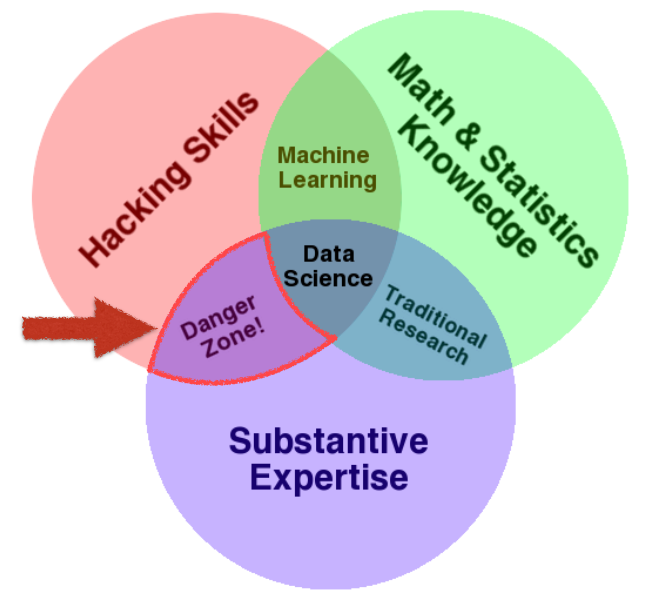
圖解資料科學,紅色部分為資料科學的danger zone
舉一個例子,利用 R 語言隨機生成 10 萬組 1999 – 2009 年的亂數資料,拿這 10 萬組資料和自殺數據去計算相關係數。這 10 萬個相關係數平均值為 0,有 9 萬個相關係數介於 [-0.5, 0.5],其中有 8 個相關係數高於 0.90,只有一組也的相關係數高於0.95 (想知道模擬怎麼做,可以參考筆者的R code),如下圖所示:
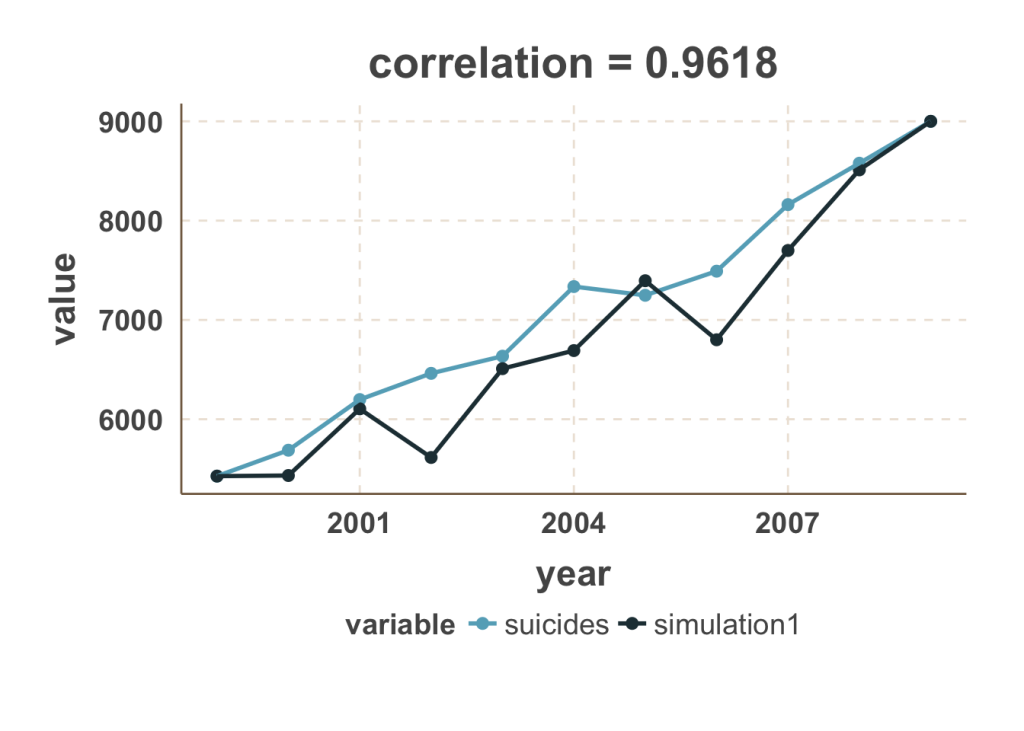
「上吊自殺 vs. 模擬數據」 (從10萬筆亂數資料中取出相關性最高者,相關係數 = 0.9618)
也就是說,透過不斷地產生亂數資料,大約每 10 萬次就可以找到一組和上吊自殺資料有強烈相關的模擬資料。即便你手上的數據和上吊自殺的數據完全無關,只要資料來源夠多,你就會有很高的機率找到強烈相關,這種現象在大數據時代將會頻繁的發生。這種相關性,稱 偽相關 (spurious correlations),是經典的資料科學Danger Zone,它可以大幅改善預測模型的精準度 (強相關可以做精準預測),但卻完全無法幫助企業進行決策,反而有可能會幫倒忙。
只有成功,才會成為案例
偽相關 跟著名的「啤酒與尿布」、「颶風與草莓夾心酥」有什麼不一樣?從技術的觀點來說,他們是一樣的,他們都是透過 Data Mining 從巨量資料中,比對兩兩資料欄位所找出來的強烈相關。但是啤酒與尿布成為人人傳頌的案例,自殺與科研經費卻只會被當作笑話看。透過筆者的模擬示範,可以預期數據來源越多,發現強烈偽相關的頻率越高。
部份教科書寫到這邊通常會再次強調「相關不等於因果,多想兩分鐘,別看到相關就開槍」,然後就到此為止,謝謝大家。究竟該怎麼驗證 Data Mining 到的相關性是否能作為商業策略的因果關係?辦法是有的,而且只需要上過一個學期的統計課就會的東西,給一個關鍵字 AB Test。
筆者即將要在 DSP 開課 (模型思考團訓班) 的主題就是講AB Test,有興趣可以來聽聽喔!

工商服務:筆者參與規劃的資料科學課程 XD
近期迴響