隨著年底直轄市長/縣市長選舉的逼近,在我看來利用資料學方法規劃選舉策略是很有潛力的。我以沈富雄先生宣布參選參選台北市長後,TVBS 於6月21日所做的民調數據為基礎,再加上台北市統計資料庫查詢系統,利用Gibbs sampling的概念將民調結果的表2-1至表2-6回推成拿不到的原始民調數據,數據大致如下表所示:
表1:台北市長選情民調數據範例
| 支持者 | 性別 | 年齡 | 地區 | 學歷 | 省籍 | 政黨傾向 |
|---|---|---|---|---|---|---|
| 連勝文 | 女性 | 30+ | 中山大同 | 高中 | 閩南 | 中立 |
| 柯文哲 | 男性 | 50+ | 士林北投 | 大專 | 客家 | 民進黨 |
| 柯文哲 | 男性 | 60+ | 士林北投 | 大專 | 閩南 | 中立 |
| 柯文哲 | 女性 | 30+ | 松山信義 | 大專 | 閩南 | 民進黨 |
| 沈富雄 | 女性 | 40+ | 中山大同 | 高中 | 外省 | 中立 |
| 未決定 | 男性 | 50+ | 內湖南港 | 國中 | 其他 | 中立 |
參考日前由 OSSF 在中研院舉辦的 Data Science with R Workshop (簡報),在介紹Data mining 方法時提到的分類與迴歸樹 (Classification and Regression Trees, CART) 進行分析,如下圖所示:
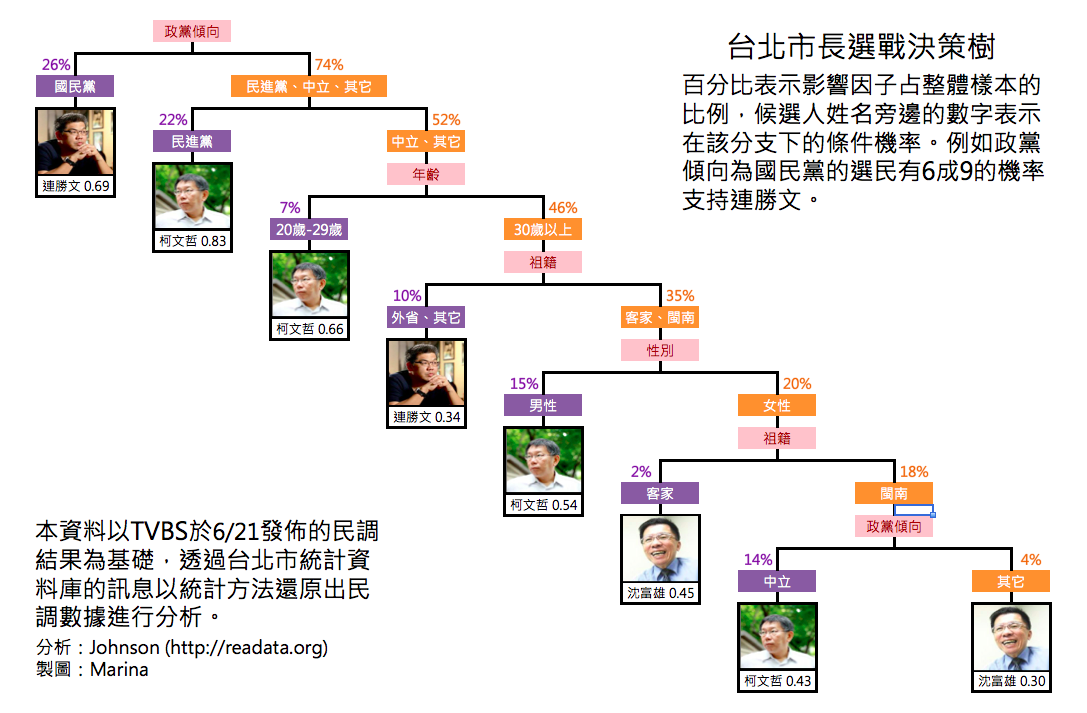
台北市長選戰決策樹
自左上而右下觀察這棵決策樹,可以發現影響選民支持度最重要的變數終究是政黨偏好,傾向於國民黨者對於連勝文的支持率為 0.69,傾向民進黨者對柯文哲的支持率則為 0.83。至於自稱中立與傾向其他政黨 (包含台聯、親民黨、新黨、無黨聯盟、綠黨與拒答) 者當中,20-29歲的年輕人有很大的比例的支持柯文哲 (0.66),30歲以上的人則依據祖籍、性別的不同對於連勝文、柯文哲、沈富雄各有所好。有趣的是30歲以上、祖籍為閩南、客家的選民中,柯文哲顯然更受到男性支持 (0.54);同樣在30歲以上、祖籍為外省、其他的族群中,連勝文的支持率為34%。至於選民的教育程度、居住地區等訊息屬於相對次要的影響因子(雖然說是次要因子,但仍影響了一成以上的選票),則能顯示諸如:1. 連、柯的鐵票族群細目;2. 沈富雄從連、柯二人手中轉移的潛在選票族群;以及 3. 未表態選民的特徵等訊息。為了不讓決策樹解釋過於冗長難懂,在此保留那些複雜的細節。
回到我想討論的主軸,資料科學有什麼潛力來幫助選舉策略規劃?根據我日前在政治大學談到資料科學與媒體分析的概述:資料科學係指針對特定問題 (在此指某種選舉方針) 規劃資料的收集、萃取、建模、再提供決策的一門學問。再講深入一點,訓練有素的資料科學家能夠針對問題規劃出:1. 該蒐集那些資料、如何蒐集正確的資料; 2. 從幾百筆、幾萬筆、幾千萬筆資料中進行整理、剖析; 3. 透過統計建模從大量的資料中發現洞見,進而提供決策方針。依此定義,資料科學家自然有助於選戰團隊的策略規劃。譬如偵測出各種游移選民的特徵與偏好、鞏固票倉的策略、競選行程路線最佳化…等等,都能夠讓資料科學家佔有一席之地。
對於資料科學家養成內容感興趣的讀者,請參考中研院資訊科學所陳昇瑋老師的專訪。此外,如果想進一步接觸資料科學養成課程的同好近期 TW.R 社群展開了一系列免費的資料科學上手課程,詳見TW.R 臉書頁面以及活動meetup。
近期迴響