近期服貿議題越演越烈,自318學生佔領國會,324 學生攻佔行政院與強制驅離事件發生後。我以為身為一個統計人,應該用自己的專長來關心這個議題。有鑑於此,我問自己一個問題:抗議現場的情況與各家媒體報導的真實性為何?
事實上,討論真實性這種虛無飄渺的概念並不容易,所以我退而求其次考慮比較能夠量化的問題,即報導之間的關聯性。
有了這個想法之後,我蒐集了g0v.today提供的現場文字轉播資料,學生族群常用的PTT服貿版資料,以及幾家新聞的報導資料進行初步分析,3/25號晚上在臉書上發布了以下這張實驗性分析圖,並且徵求夥伴幫忙擷取各家媒體更完整的服貿報導資料。
這兩天,感謝很多人熱心的幫忙。無論是資料的提供、文本挖掘技術的交流還是媒體分析經驗的分享等等 (感謝Ronny, Marsan, 文心, Toley and 家齊)。我用更嚴謹的方法得到了以下關聯性分析結果,
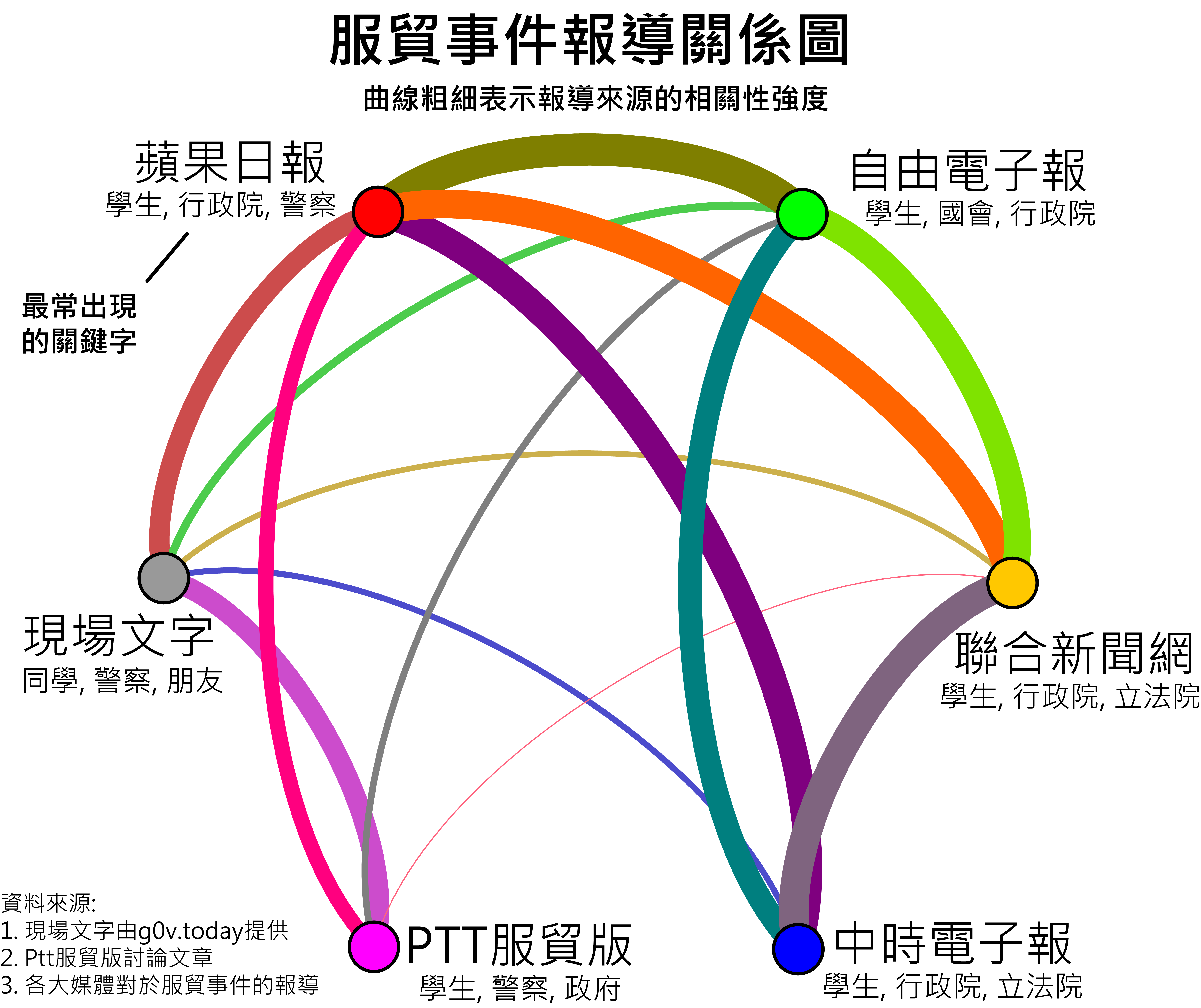
先說圖怎麼看,曲線的粗細表示報導來源之間的相關性強度。再說我的主要發現:
- 蘋果日報與所有報導來源都有高度的關聯性
- 報導來源可以分成左右兩群,右半邊是一般的媒體報導,左半邊則是蘋果日報與民間報導。
- 儘管PTT與現場文字轉播的關聯性在所有報導來源中是最高的。但是,PTT與各大新聞媒體的關聯性都偏低。
至於分析方法,簡單來說就是以關鍵字找相似度。我用R當作主要分析工具,參考家齊與嘉葳參與Taiwan R user group在MLDM Monday meetup關於文本挖掘的演講 (1 & 2) 進行文本分析,分析出各家媒體報導的關鍵字詞頻,再利用我做生物統計最熟悉的相似度指標來計算各家報導的關聯性。
最後,我是打算用作研究的態度來玩這個題目。所以必須談談現在遇到的困難之處,希望有人能給點意見。最主要的困難點在於:「現場文字播報忠實的呈現現場結果,但相較一般新聞報導而言,有口語化過度的問題」。口語化的問題必然與媒體使用的文字有所不同,這個效應與媒體選擇性報導的差異混淆在一起。解決的辦法目前想嘗試:
- 確實移除口語化關鍵字之後,再計算相似度 (部分完成)
- 加入民間媒體進行分析,ex: 台大新聞E論壇 (周末動工)
對於上述分析有問題,或是我的後續研究有所建議者,不吝指教,謝謝。




近期迴響