近期服貿議題越演越烈,自318學生佔領國會,324 學生攻佔行政院與強制驅離事件發生後。我以為身為一個統計人,應該用自己的專長來關心這個議題。有鑑於此,我問自己一個問題:抗議現場的情況與各家媒體報導的真實性為何?
事實上,討論真實性這種虛無飄渺的概念並不容易,所以我退而求其次考慮比較能夠量化的問題,即報導之間的關聯性。
有了這個想法之後,我蒐集了g0v.today提供的現場文字轉播資料,學生族群常用的PTT服貿版資料,以及幾家新聞的報導資料進行初步分析,3/25號晚上在臉書上發布了以下這張實驗性分析圖,並且徵求夥伴幫忙擷取各家媒體更完整的服貿報導資料。
這兩天,感謝很多人熱心的幫忙。無論是資料的提供、文本挖掘技術的交流還是媒體分析經驗的分享等等 (感謝Ronny, Marsan, 文心, Toley and 家齊)。我用更嚴謹的方法得到了以下關聯性分析結果,
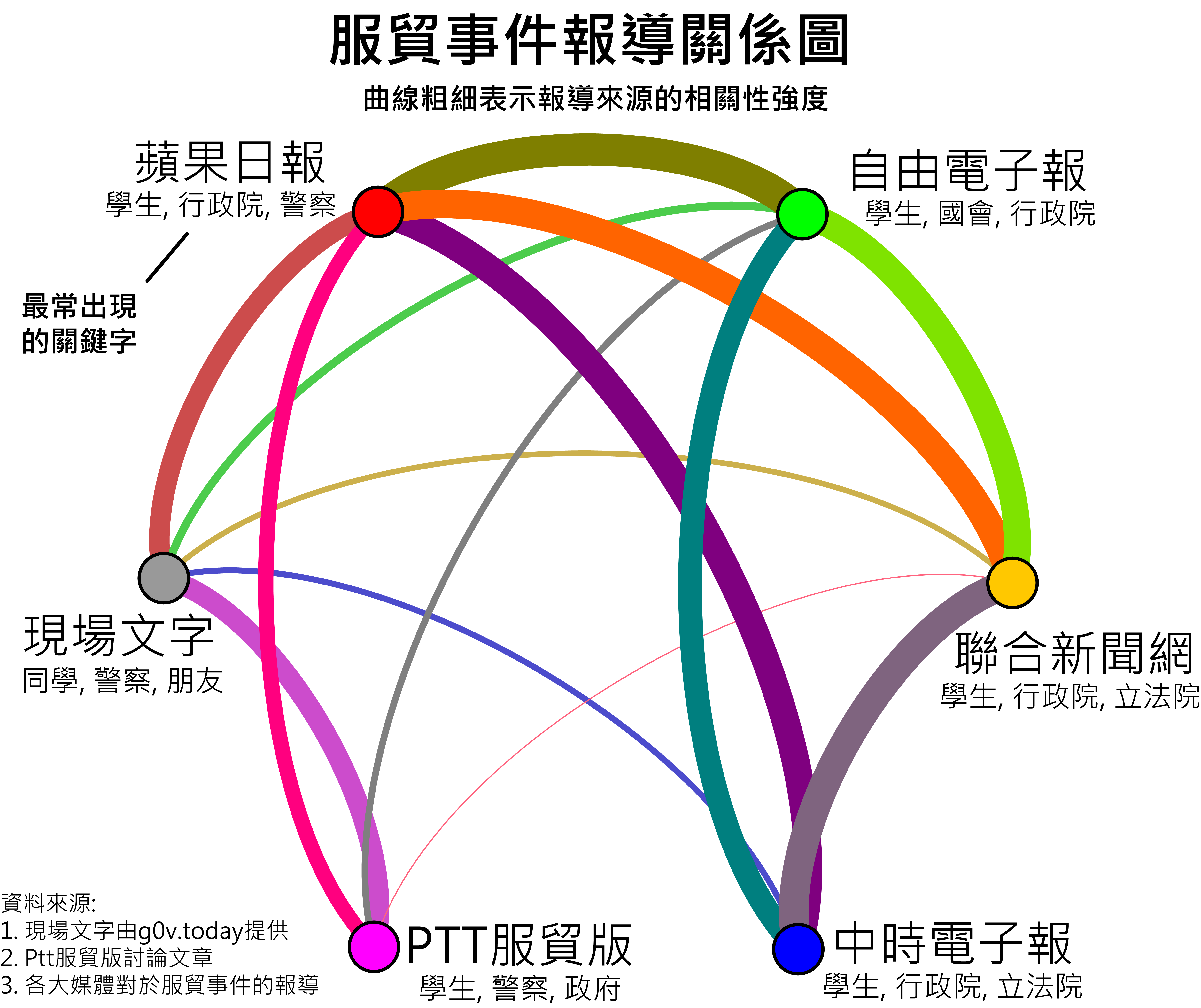
先說圖怎麼看,曲線的粗細表示報導來源之間的相關性強度。再說我的主要發現:
- 蘋果日報與所有報導來源都有高度的關聯性
- 報導來源可以分成左右兩群,右半邊是一般的媒體報導,左半邊則是蘋果日報與民間報導。
- 儘管PTT與現場文字轉播的關聯性在所有報導來源中是最高的。但是,PTT與各大新聞媒體的關聯性都偏低。
至於分析方法,簡單來說就是以關鍵字找相似度。我用R當作主要分析工具,參考家齊與嘉葳參與Taiwan R user group在MLDM Monday meetup關於文本挖掘的演講 (1 & 2) 進行文本分析,分析出各家媒體報導的關鍵字詞頻,再利用我做生物統計最熟悉的相似度指標來計算各家報導的關聯性。
最後,我是打算用作研究的態度來玩這個題目。所以必須談談現在遇到的困難之處,希望有人能給點意見。最主要的困難點在於:「現場文字播報忠實的呈現現場結果,但相較一般新聞報導而言,有口語化過度的問題」。口語化的問題必然與媒體使用的文字有所不同,這個效應與媒體選擇性報導的差異混淆在一起。解決的辦法目前想嘗試:
- 確實移除口語化關鍵字之後,再計算相似度 (部分完成)
- 加入民間媒體進行分析,ex: 台大新聞E論壇 (周末動工)
對於上述分析有問題,或是我的後續研究有所建議者,不吝指教,謝謝。
不好意思對生物統計不太熟悉,想請教這個關聯性該怎麼理解比較好,關聯性越高,是指報導的文字內容越像嗎?
你說得是對的,更精確的說關聯性越高表示報導來源所是用的字頻分布越像。至於我用什麼樣的方式計算關聯性,給一個key word : Morisita-Horn index。
後續研究可以考慮由文章語意分析立場為「支持或反對」的方向,感覺會滿有趣的
除了facebook上的民間媒體,像是新頭殼 newtalk ( http://newtalk.tw/ )或是關鍵評論網 The News Lens ( http://www.thenewslens.com/ )這些獨立媒體也可以加進去。獨立媒體在這次的事件關注跟現場消息轉送上積極度比傳統媒體來的高許多。
謝謝您的建議,希望下次公佈的分析結果可以把他們加進來
我想從網絡密度(報導之間的關聯性)與中心性(目前已知是蘋果日報為中心)兩個層面來觀察。
我們知道服貿議題有各種面向,國家認同、民主定義、經濟制度……
但是從圖中的關鍵字來看,媒體多僅報導事件與人物,受限篇幅與新聞傳遞社會"當下"的任務,平面媒體沒辦法進一步闡述議題背後的脈絡。
這就造成左右兩群的報導相關度低。
您原初的研究問題是:抗議現場的情況與各家媒體報導的真實性為何。從圖中,我們已經得知,PTT與文字轉播比較符合現場真實性,而其他平面媒體會根據報社立場與記者詮釋面向的不同,各自呈現不同的報導角度。
如果可以,我想將網絡加上時間變數,那麼隨著事件的發展與沉寂,網絡會漸漸越來越不一樣,網絡密度(報導之間的關聯性)會越來越低。因此,我會好奇事件沉寂後,議題的走向為和?從不同時間的網絡關鍵字變化、或增減網絡中的媒體,或可略知端倪。
此外,我又很好奇,不同的媒體意見領袖,對其他媒體會造成什麼不同的影響?
目前我們已知,蘋果日報是服貿議題的新聞散播中心,它既具備大眾媒體身分,又具備鄉民性、長時間跟隨運動發展,因此得以最大程度地完整呈現事件的各個脈絡。
但是我們無法追蹤新聞的來源、路徑與散播方向。是蘋果記者親自蹲點採訪,還是抄PTT,還是從PTT與文字轉播找線索、再去現場採訪?
再者,如果今天是聯合報或其他媒體扮演中心角色,會不會影響議題散播的範圍與議題存活的生命?
有些問題可能會用到不同的方法來調查。總之,很喜歡這個研究。
你好!! 我是國立東華大學應用數學系統計碩士班的學生
目前在做text mining的探討(非常初學者階段…)
在今年的南區研討會,有看到你的文章spadeR (但我擔任工作人員沒有聽到你的Session)
我的指導教授 希望我能夠操作一遍您的主題
但是我在R裡面的package找不到spadeR,所以冒昧打擾你…
非常抱歉打擾了
謝謝您
我還沒有把 spadeR 放到CRAN上面,你可以到這裡使用我們實驗室開發的線上工具: https://johnson.shinyapps.io/spadeR/。
另外,有關於 text mining 的分析內容,可以參考我的github repo: https://github.com/JohnsonHsieh/study-area-statR。
非常感謝你。
You are a good allied statistician
You can find good job in us if you can communicate in English
Take care of your talent
Prof Wang
Dear Prof Wang,
Thank you for your compliment,
I’ll keep the pursuit of progress not only Statistics and English
Johnson
[…] (原文載於讀數一格) […]