六月初偕同御言堂總經理劉嘉凱 (CK) 先生以及 Etu 負責人蔣居裕 (Fred) 代表 Data Science Program (DSP) 到交大統計所演講的時候,跟所長黃冠華教授聊到統計所與資訊學院合作開設巨量資料分析學分學程印證了以下想法。
統計是從複雜數據中萃取出有用訊息的學問,在分析巨量資料 (big data) 的過程中,理當扮演舉足輕重的角色。然而,傳統的統計學系訓練學生的方式著重在統計工具的開發與應用上,這並不足以勝任所謂的巨量資料分析。
隨著巨量資料這個議題逐漸火熱,一個新的科學領域:資料科學 (data science) 也隨之而生,相對於統計學專注於分析方法之上,資料科學強調的是以資料解決問題的整體流程,即
1. 在該領域有深厚的專業知識,能夠將欲解決的問題以科學建模來表達。
2. 具備足夠的電腦知識與程式能力,能夠高效率的蒐集、清理、管理巨量資料。
3. 對統計方法有廣泛的瞭解,能夠快速的選用適當的統計方法,甚至是開發新的統計方法來分析資料。
4. 綜合以上三者,能夠以非技術性的語言 (譬如:資料/指標視覺化) 來闡釋分析結果,達成有效率的溝通。
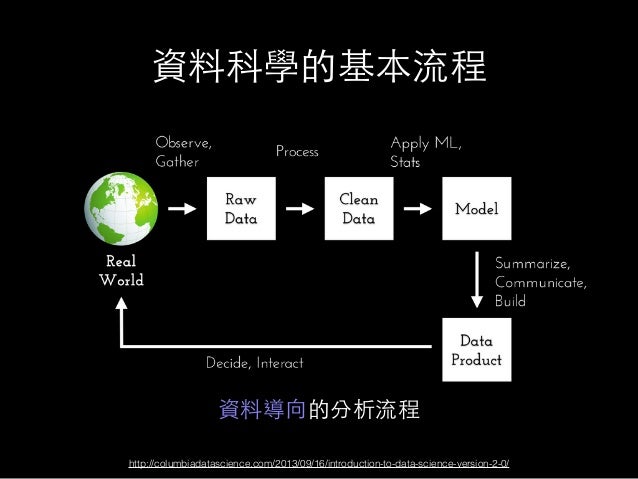
資料科學強調整個流程,統計學則強調分析 (Model) 的部分
就筆者的認知,統計學的本質和現在所謂的資料科學並無不同。然而,從幾乎所有統計教材都會引用的鳶尾花資料集 (iris data) 當作範例就可以發現,統計人太習慣於從某些領域的提問者中聽取問題、收取已經整理好的資料集 (data frame, 諸如 .txt、.csv 檔),然後再「開始做統計」。什麼時候開始,統計人自詡只需要紙筆與電腦就可以做研究,卻忘了在統計界備受尊崇的 R. A. Fisher 爵士是在農業試驗所中發展出變異數分析、實驗設計法、最大概似估計…。
或許對於一個專精於統計方法的統計人而言,這種習慣並無不妥。但是在現今巨量資料的浪潮上,到處充斥著結構化、半結構化與非結構化的資料 (詳見 Fred 豢養的雲中象)。這類資料跟以往統計教科書裡面經由篩選與處理後的資料完全不同。以企業內部的結構化資料為例,當企業負責人抱著 SQL Database 或 Data Warehouse 裡面滿滿的資料來請統計專家做問題諮詢時,該怎麼回應? 如果是非結構化的圖檔、影像檔,統計專家又該怎麼回應? 就像林禎舜師兄在MLDM Monday的演講中提到的一個概念:就現今以資料解決問題的話語權而言,(相對於資訊科學) 統計學的話語權是逐漸式微的 (因為統計人無法處理第一線的資料)。
我的經驗是統計人要拋開傳統教科書對於 data 就是一個data frame 的認知,瞭解 data 的原貌是真實世界的一種記錄方式,它可以是數字、文字、聲音、影像、氣味、建築物…。真真切切的去貼近真實世界、去貼近第一手資料,用最直覺的方式體會所知的統計方法,就會發現這些方法的精神其實可以應用在各式各樣的資料上。
下一篇,將會具體的談到統計人進入Big data / Data science 的建議。
近期迴響