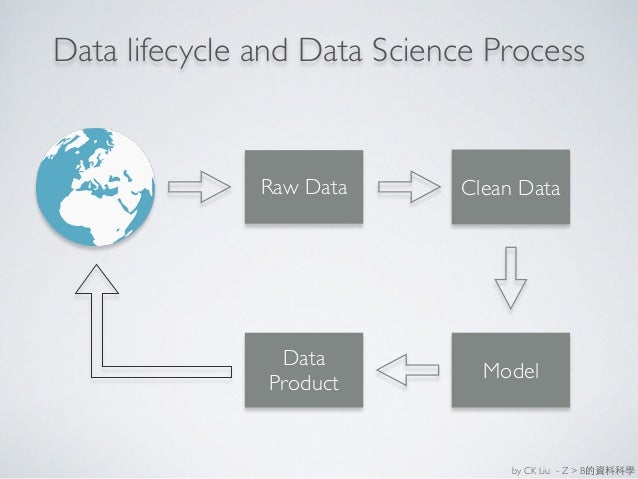
Big data已經熱一陣子了,市面上許多企業紛紛提出各種Big data solutions,究竟這些solutions到底是在解決什麼樣的問題?筆者將近期對於 Big data的觀察心得做一點整理,分享給大家。就資料分析的觀點,筆者認為現今 Big data 面對的問題可以分成三種類型:

Type A. Big data 問題跟 Small data 是一樣的
無論資料量級的大小,資料分析重視如何展現資料的特徵。展示特徵的方法首要是對資料進行適當的疏理 (subsetting / summarise),整理出能夠進行資料建模 (modeling) 資料表、具代表意義的指標,或是資料視覺化圖表。儘管資料的問題本質一樣,但是在Big data上,需要分散式資料庫 (distributed database) 上的資料處理工具諸如Hive, impala, teradata …等才能實現。如果想要在R語言的環境下,執行量級較大 (GB層級) 的資料疏理 (Data ETL),可以參考dplyr, data.table, sparkR等套件。
Type B. Big data 問題等同一大群 Small data 的問題
對於Big data進行分析的資料模型,可以由若干Small data models所組成的元件來表示。在這種情況下,分散式運算 (distributed computing) 是為必要技術。如果想要在R語言的環境下執行平行運算,可以參考pbdMPI, snow, foreach, Rth等套件。
Type C. Big data 問題需要靠特製系統解決
當資料分析模型無法透過分散式運算有效解決計算效率問題,需要經常性/即時性分析整包Big data的問題屬於此類。這需要根據整體資料分析的流程特製化設計解決方案,譬如說推薦系統。如果想在R環境下嘗試輕量資料可以運行的推薦系統演算法,可以參考recommenderlab套件。
這三種資料分析類型,其要求的 Big data 理論、技術、工具不盡相同。如果您是正在尋求所謂Big data solution的企業,筆者建議先檢驗您的資料量級是不是 Big data,接著再思考您面對的資料分析問題是哪一種類型,進而尋求解決方案。
日前一篇對知名資料科學家工具開發專家Hadley Wickham的採訪報導中,提到一個有趣的數字,90%的Big data問題屬於Type A,9%的問題屬於Type B,其餘的部分則屬於Type C。姑且不論這數字的精確性,從Data life cycle的觀點,抑或從企業的資料成熟度來看,不妨依循 A -> B -> C 的流程,一步一步尋求解決方案囉。
{kind=link}
近期迴響