美國著名文豪馬克‧吐溫留下一段經典名句:「謊言有三種:謊言、該死的謊言與統計數字 (There are three kinds of lies: lies, damned lies, and statistics.)。」目的在於諷刺那些使用統計數據支持卻毫無說服力的報告,以及貶低反對立場的統計結論。我想要用一個發生在台灣的真實案例來呼應馬克‧吐溫的哲言。
以下是2012年3月27日自由時報的頭條新聞,主要是說明2010年度最窮的5%家庭平均年所得僅4.6萬元,對比最富的5%家庭平均年所得429.4萬元,差距達到93倍,比去年的75倍差距來得更高。

自由時報-貧富差距飆至93倍 歷史新高 http://www.libertytimes.com.tw/2012/new/mar/27/today-t3.htm
再看一則當時經建會主委尹啟銘先生的文章,時間是在上一則新聞過後的兩天 (3/29) 。主要是在闡述國際上常用的是五等分法,即最窮與最富的20%來比較,得貧富差距為6.19倍,相比去年的6.34倍來得低。至於使用最窮與最富的5%來衡量貧富差距(二十等分法)在國際上缺乏理論的根據和無公信力作基礎,因此國際上幾乎無人採用。

尹啟銘-讓國人正確了解當前貧富差距, http://www.ndc.gov.tw/m1.aspx?sNo=0016735
事實上,這種爭論每年都會登上新聞版面,譬如自由時報2013/06/10的頭版新聞
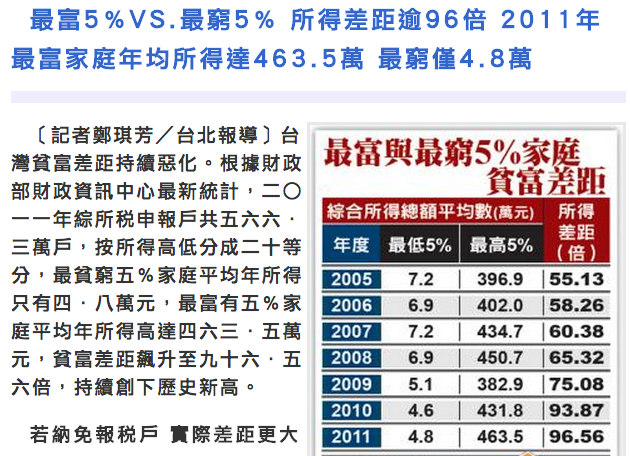
自由時報-最富5%VS.最窮5% 所得差距逾96倍 http://www.libertytimes.com.tw/2013/new/jun/10/today-t2.htm
再如TVBS在2014/01/09的影音版新聞
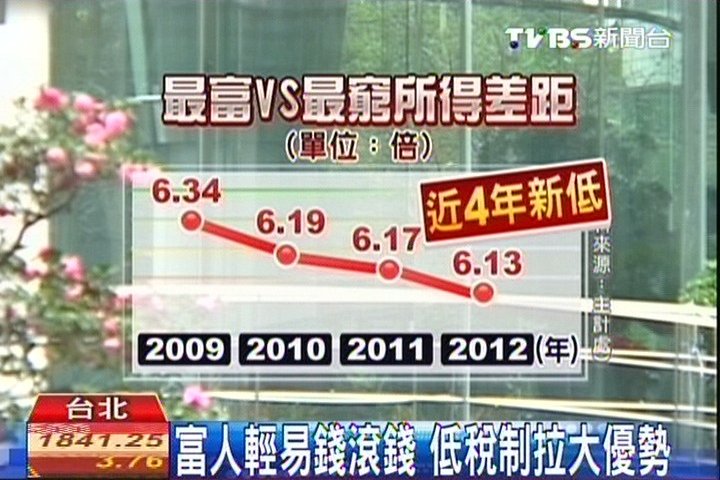
貧富差距擴大? 逾9成民眾:嚴重!http://news.tvbs.com.tw/entry/517145
平平都是相同來源的每戶年平均所得資料,究竟怎麼一回事?如何從這種裡用統計指標 (statistical index) 各說各話的情勢中明辨是非,是我所關心的問題。從我整理自上述新聞以及官方公佈的家庭收支調查報告勉強可以看出一點端倪。
| 年度(萬元) | 94年 | 95年 | 96年 | 97年 | 98年 | 99年 | 100年 |
| 最低5% | 7.2 | 6.9 | 7.2 | 6.9 | 5.1 | 4.6 | 4.8 |
| 最低20% | 29.8 | 30.4 | 31.2 | 30.4 | 28.2 | 28.9 | 29.6 |
| 最高20% | 180 | 183 | 187 | 184 | 179 | 187 | 183 |
| 最高5% | 397 | 402 | 435 | 451 | 383 | 432 | 464 |
看得出來嗎?除了2009年 (民國98年) 國際金融危機之外,最低20%與最高20%的家庭收入2005年以來大致上並無太大的改變。但是最低5%在2009年之後明顯的下降,最高5%則有明顯的上升趨勢。
最後,我參考美國每戶收入的直方圖,再根據二十等分位的統計指標來回推台灣在2005與2011年的每戶年平均收入分布圖。先看下圖的右半部 (富人部分),可以發現藍色 (2011年) 的圖形的右邊拖著一條比紅色 (2005年) 圖形要高的尾巴;再看左半部 (窮人部分),雖然有一點不明顯,不過還是可以發現藍色比紅色圖形更靠左邊。與其追究政府官員還是新聞報導的統計指標孰是孰非,我以為透過這張分布圖來回答更加明確。這邊用統計人的角度murmur一下,有關單位不要只公布統計指標,Data Open吧。

台灣每戶年平均收入猜測
我寫這篇文章的主要目的,不在於討論台灣社會貧富差距 (這類的討論真的很多,光是用幾等分法來衡量貧富差距就吵不完了),而是在於呼應馬克‧吐溫的哲言。要知道,同樣的資料集可以產生各種不同的統計指標,每一種統計指標都有獨特的意義以及適用的時機。統計指標並沒有好壞之分,可惡的是因為立場的不同,而使用特定指標來做為宣傳工作的壞蛋。

近期迴響